Submitting jobs to the HPC
Overview#
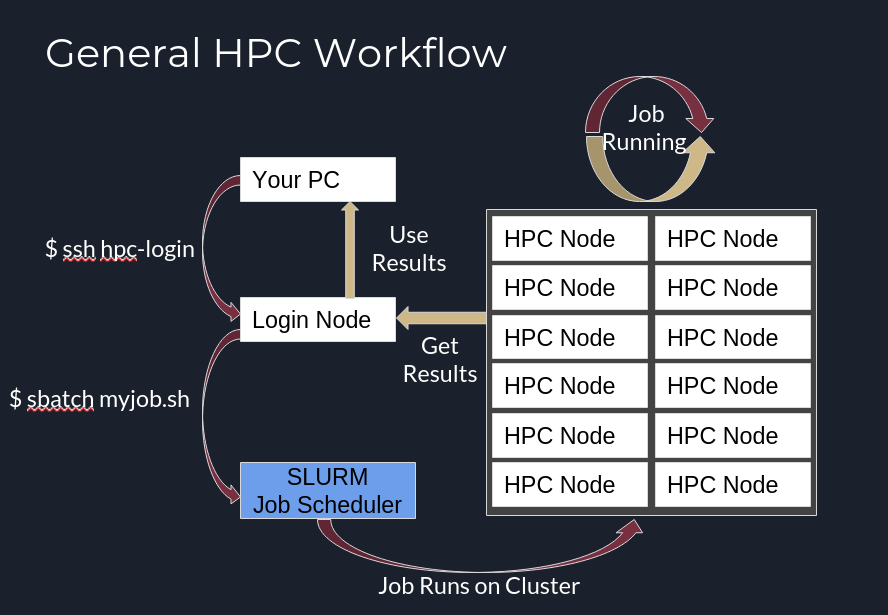
When you wish to use the High performance compute (HPC) cluster, you must create a job and submit it to our job scheduler. The scheduler helps ensure fair access to the HPC cluster by scheduling resources efficiently across the system for thousands of simultaneous jobs.
The job scheduler we use is called Slurm. This software enables us to provide large-but-finite compute resources to a large campus research community.
Depending on how you wish to use the cluster, there are two basic categories for jobs:
These are the most common type of job submitted to the HPC. The basic workflow is you set up your parameters, data, and executable up ahead-of-time and submit it our scheduler. Then, it waits in-queue for resources to be available on the cluster, starts, runs for a period of time, producing output. After the job processing finishes, you analyze the output, and repeat the process as necessary.
Interactive jobs reserve resources on the cluster for a specified period of time for researchers to work directly on compute node(s) through the command line or a graphical environment.
These jobs are generally submitted through Open OnDemand, the web portal to the HPC. If you need to interact with graphical applications such as R Studio, Jupyter Notebooks, or MATLAB, then you will need an interactive job.
Both types of jobs may not start right away upon submission. Jobs are typically queued and processed according to an algorithm to ensure fair access for all users. Your job will remain queued anywhere from a few seconds to a few hours depending on how many resources you request, which Slurm account you submit it to, and how much activity is occurring on the cluster. The average wait time is a few minutes.
Note
Be careful to not confuse user accounts with Slurm accounts. Slurm accounts are analagous to research groups, which typically each have their own dedicated queue, whereas user accounts are one-per-user.
We provide many accounts for groups of users. Any faculty, student, or guest with a user account on the HPC can submit jobs to our general access Slurm accounts. For those research groups that have bought into the HPC, we provide dedicated Slurm accounts with priority access.
Getting ready to submit#
Before submitting your job to the Slurm Scheduler, you need to do a bit of planning. This may involve trial-and-error, for which interactive jobs may be helpful. The three most salient variables are as follows:
- How long your job needs to run - Choose this value carefully. If you underestimate this value, the system will terminate your job before it completes. If you overestimate this value, your job may wait in-queue for longer than necessary. Generally, it is better to overestimate than to underestimate.
- How many compute cores and nodes your job will require - This is the level of parallelization. If your program supports running multiple threads or processes, you will need to determine how many cores to reserve in order to run most efficiently.
- How much memory your job will need - By default, the Slurm scheduler allocates 3.9GB per compute core that you allocate (this, however, varies among Slurm accounts; e.g., the backfill queue allocates only 1.9GB per core). The default is enough for most job, but you can increase this value independently of the number of cores if your job requires more memory.
- If your job will need access to special features - Your job may need access to GPUs or to nodes with specific processor models. You can specify these as constraints when you submit your job.
Choose a Slurm Account#
You must submit your job to a Slurm Account. Each account has different limitations and parameters. If you have purchased resources on the HPC, you will have access to a dedicated account for your research group. All users will have access to our general access accounts:
| Account Name | Time Limit | Job profile |
|---|---|---|
| genacc_q | Two weeks | MPI jobs that will run for up to two weeks |
| backfill | Four hours | short-running MPI jobs (up to four hours) |
| backfill2 | Four hours | short-running MPI jobs (up to four hours) |
| condor | 90 days | long running jobs that do not need to use MPI |
| quicktest | 10 minutes | testing your jobs |
You can see a list of Slurm Accounts on our website or by running the following command on an HPC login node:
Submitting a non-interactive job to the Slurm scheduler#
Submitting a non-interactive job to our HPC scheduler, Slurm, requires that you have a "submit script". The details for creating a submit script are below.
A submit script is a simple text file that contains your job parameters and commands you wish to execute as part of your job. You can also load environment modules, set environment variables, or job preparation tasks inside your submit script.
Example: Submitting trap#
This example demonstrates how to submit the trap application from our compilation guide. To follow along, complete the steps in that guide and then return here to submit your job.
You can use a text editor such as nano, vim, or emacs to create a submit script named submit_trap.sh in your home directory with the following parameters:
There are three blocks in a typical submit script:
-
The first line of the script is called a "shebang", and it sets the interpreter. Generally, this will be
#!/bin/bash, but it can be other interpreters (e.g.,#!/bin/cshor#!/usr/bin/env python3). -
The next block specifies the job parameters you need for the Slurm scheduler. These always start with
#SBATCHfollowed by the command-line option. For more details about the Slurm scheduler options, refer to our reference guide or the Slurm documentation. -
The last block consists of the actual commands you want to execute. In this example, we run two commands:
module load intel mvapich/2.3.5: This loads the environment module for the Intel MVAPICH2 libraries.srun trap-mpicvh2: Run your custom compiledtrap-mpichv2program usingsrun.
Save the file and close whatever text editor you used to create it. Then submit your job to the cluster using the sbatch
command:
When you run this command, you will see something similar to the following:
This means your job was accepted by the Slurm scheduler, and your job is now queued in our genacc_q Slurm account, and
will run as soon as resources become available. This can take anywhere from a few seconds to several days, depending on
how many resources (time, memory, cores) your job requested, along with some other variables. You will receive an email
when your job starts.
Warning
If you receive any other output from the sbatch command, check the
troubleshooting section in our reference guide.
You can see the status of your job by running squeue --me:
If you do not see your job listed, it has either finished or failed.
Viewing Job Output#
When your job completes, you will receive an email from the Slurm scheduler with the status and other details. Either way an output file will appear in your home directory (or whatever path you submitted your job from). The file name(s) will be slurm-[JOB_ID].out. You can view this file with common Linux tools such as more, less, cat, or editors such as vim, nano, or emacs.
In this example, the output will be the output from our trap script. It will also contain any error output that the program generated.
Note
By default, Slurm combines error (STDERR) and output (STDOUT) in the same file. You can separate your error output from your standard output if your workflow requires it. Add the following lines to your submit script:
Submitting an interactive job to the Slurm scheduler#
Note
We recommend using our Open OnDemand service for interactive jobs, because it makes running interactive jobs much simpler.
To run an interactive job from one of the login nodes, use srun --pty directly from the terminal prompt, generally
followed by a shell environment. The most basic syntax that the Slurm scheduler accepts is as follows:
When you run this command, you will see the following output:
After some period (generally a few minutes), you will see the following appear:
Notice that the hostname has changed once your job starts running. You are now on a compute node instead of the login
node. You can now work interactively. When you are ready to finish your job, type exit, and the scheduler will
return your session to the login node.
Specifying Slurm options in interactive jobs#
In the above example, we didn't specify any parameters for the Slurm scheduler, so it used the default values. If you want
to run your job in a custom Slurm account or set a custom time limit, you will need to pass command line options to the
srun command.
For example, we specify a time-limit of three hours, number of processes of 12, and run in the backfill2 Slurm account below:
Note
Notice that the option identifiers for interactive jobs are the same as we put in our non-interactive submit script,
except passed as command-line options instead of prefixed with #SBATCH.
Further reading#
In this page, we covered the basics of submitting jobs to the Slurm scheduler. For more information and options, refer the following resources: