HPC Benchmarks
Disclaimer
These benchmarks were updated in mid-2021. We are working on re-running them as of November 2022.
Compute node benchmarks#
WRF Compute node benchmarks#
To determine the computational performance and scaling of systems available on the HPC, we used the benchmarking tools available from WRF, the Weather Research and Forecasting model1. In our tests, we looked at the GFlops for three different compilers: GNU, Intel, and PGI.
We coupled each of these with both OpenMPI or MVAPICH2, which gave us a total of six combinations. We tested each of these across 4, 16, 64, 144, 256, 400, and 576 processors. The scaling of each of these compilers is shown for all the available hardware on the HPC, which is categorized according to the year that it was introduced (2012-2019).
We show two variants of the same data below in the benchmark results section. First, we show each compiler combination changes across upgrades (e.g. GNU OpenMPI, Intel MVAPICH2, PGI OpenMPI, etc.), so we have six plots. One of these plots details the scaling across every year's hardware for one compiler. Then, we show the inverse, where four plots correspond to each year's hardware. One of these plots shows the compiler performance for that year.
WRF configuration#
WRF provides two example data sets intended specifically for benchmarking purposes. We use the lower resolution data set
(12km CONUS, Oct. 2001) in our tests. We follow most of the
instructions outlined on the WRF benchmarking page. During the configuration
stages, we use the dmpar options for each compiler under Linux x86_64, using basic nesting.
We then modify the configure.wrf file to change a few compiler flags, where most importantly we remove the flags,
-f90=$(SFC) and -cc=$(SCC), which ensures that distributed memory parallel processing is used rather than shared memory
parallel processing. After configuring and compiling, we submit a Slurm submit script with some combination of the options
mentioned in the Introduction; i.e., compiler, number of processors, hardware year. We also modify the namelist.input file
to accounts for the number of processors in each dimension; the values nprox_x and nproc_y. Following the successful
execution of the program, the results are recorded in a publicly available directory on our storage system:
Specific results are found in the subdirectories. For example, the results for GNU OpenMPI for the hardware year 2010 using four processors are located in the directory:
Specific timing information is found in the file rs.error.0000 in each of the subdirectories. To find GFLOPS, we used
the stats.awk program provided by WRF, using the command:
However, this command is contained in the Python script used to calculate the GFlops for all configurations. A MATLAB script is then used to plot these results.
Post-processing tools#
All the above described post-processing tools are publicly available on our storage system:
They are also available via our GIT repository2. There should be no need to reconfigure/recompile WRF when benchmarking on the HPC for the six compiler combinations described above, because these are already available in the path:
Using these tools requires some slight modifications in order to properly place the output from the WRF benchmark tests and post-processing into your home directory, which will be outlined after the below explanations for each tool.
Submit script#
The submit script submitJob.sh creates a new directory, adds all the necessary symlinks, then creates a Slurm script
for the job. This script takes three required and one optional command-line arguments:
- The compiler combination
- The year of the compute nodes being tested
- The number of processors requested
- The estimated time to complete the job (2 hours by default, but this can be reduced if more processors are used)
It may be useful to refer to the comments at the top of the script, where all the parameters are briefly explained.
After completion of the job, there will be two large files in the output directory. These are not necessary to retain.
They will be identical regardless of job configuration: wrfout_d01_2001-10-25_00_00_00 and wrfout_d01_2001-10-25_03_00_00.
Feel free to delete them.
scanResults.py and generateFigures.m scripts#
The two other scripts were used primarily to generate the figures shown below, though some users may find them useful.
The scanResults.py script crawls through the simulation results and finds the timing information, making use of the calcGF.sh
and stats.awk files (the latter two scripts are not meant to be used directly by the user). This script outputs a file
that contains the compiler combination, the year, the number of processors, the average time per simulation time step, and the
speed in GFlops for each job configuration.
The generateFigures.m script is MATLAB script that uses the results from scanResults.py to generate a plot of the data.
Instructions for running the benchmark scripts#
Here, we show you how to modify each of the scripts to output data to your home directory. Note that you must copy each of these scripts to your home directory and apply execute permissions. Though the following directory configuration may not be ideal for all users, they aid in explaining the basics of what directory paths need to be changed in each script.
- Create the directory structure:
- Copy the tools from the public benchmark directory to your home directory:
- Edit the
$HOME/WRF/tools/submitJob.shfile. - Change the
userOutputDirvariable to the output subdirectory in your home directory:$HOME/WRF/output - Change the
queuevariable tobackfill2 - Edit the
calcGF.shfile, and change thepublishedResultsvariable to$HOME/WRF/output - Edit the
scanResults.pyfile. The compilers, years, and processor arrays may need to be changed to reflect your suite of test configurations. No directory variables need to be modified in this file. - Edit the
generateFigures.m. Change thefigureFolderto$HOME/WRF/figs. The compilerNames, titleNames, fileNames, and years arrays may also need to be changed in this file as well.
To test any changes, the recommended configuration for the submit script is the GNU OpenMPI using the 2012 compute nodes
with 4 or 16 processors. These jobs should complete fairly quickly with minimal wait times, even in the backfill2 or genacc
Slurm accounts.
Benchmark results by year#
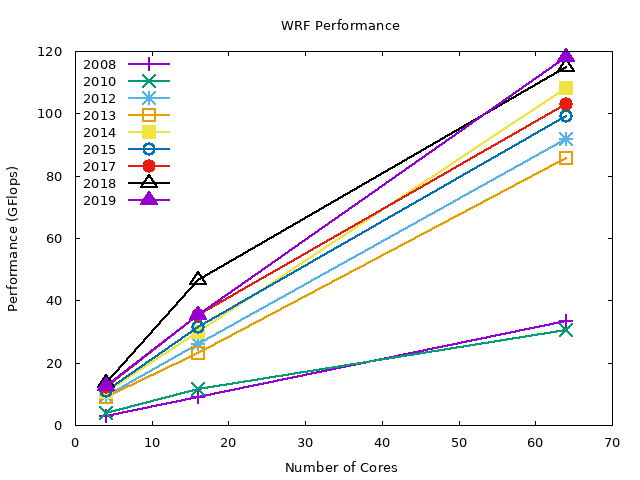
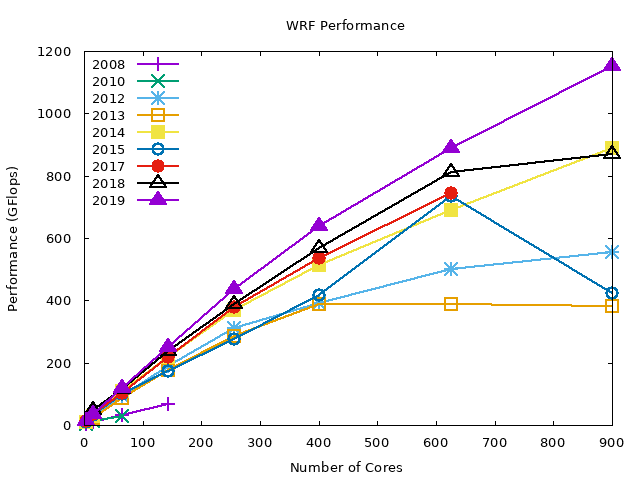
The following graphs summarize the performance of WRF on different hardware configurations in the HPC cluster grouped by year that the compute nodes were brought into service. The y axis shows the performance in GFlops3, and the higher the value, the better the performance.
The graphs below show the benchmark results for lower core counts. The results are averaged over all compilers (GNU, Intel, and PGI) and parallel runtime libraries (OpenMPI and MVAPICH2).
Benchmark results by compiler#
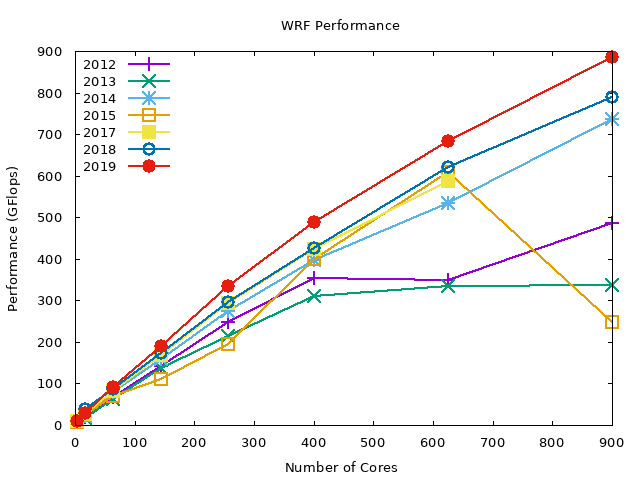
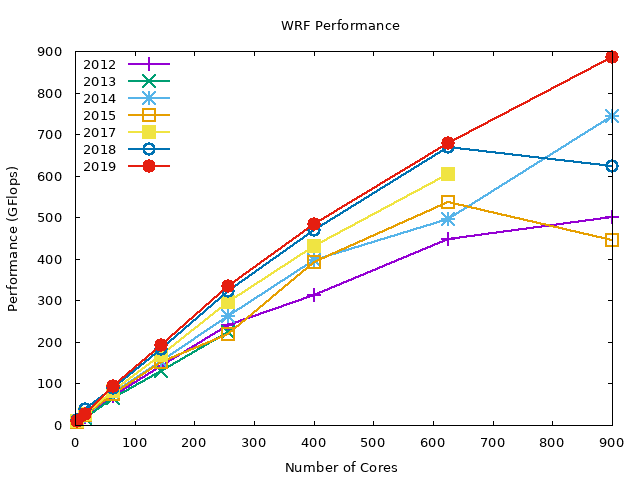
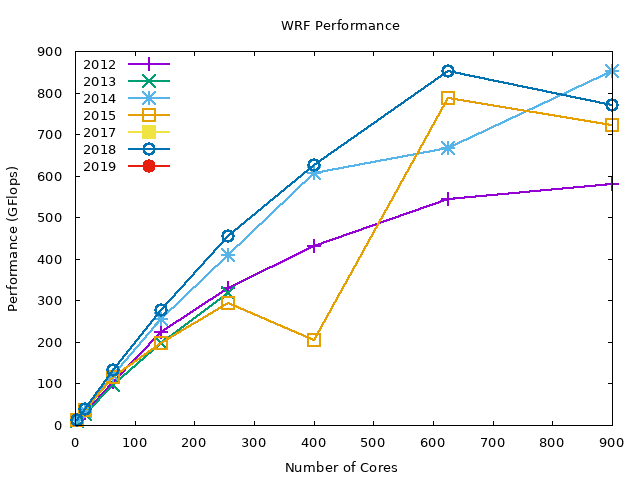
The following graphs show the data in the above graph by compiler. Note that we are missing the PGI compiler benchmarks for the 2019 compute nodes.
In summary, WRF performs best with Intel compilers (about 2x performance gain compared to GNU compilers), and the PGI compiler performance is in-between the GNU and Intel compilers. OpenMPI performs slightly better than MVAPICH2 across all the compilers.
GNU OpenMPI#
GNU MVAPICH2#
Intel OpenMPI#
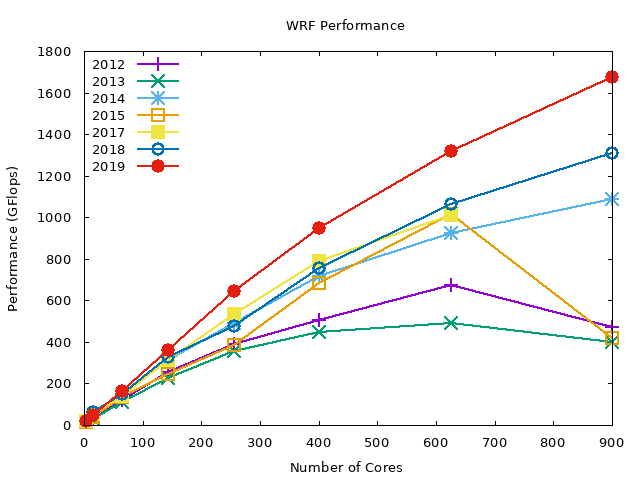
Intel MVAPICH2#
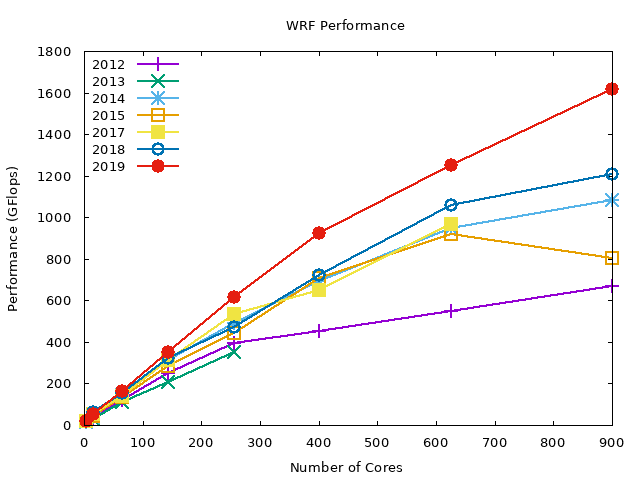
PGI OpenMPI#
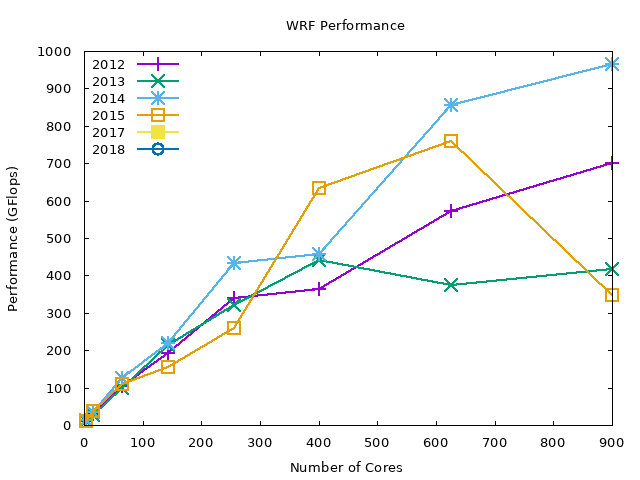
PGI MVAPICH2#
LAMMPS Compute node benchmarks#
LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) is a molecular dynamics simulation package. We chose this as a benchmark application for two reasons: (1) it is widely used in the FSU research community, and (2) it works differently than WRF depending on the type of model used.
We used the following four benchmarks provided as a part of the LAMMPS package to measure the performance of our systems:
| Benchmark | Explanation |
|---|---|
LJ |
atomic fluid, Lennard-Jones potential with 2.5 sigma cutoff (55 neighbors per atom), NVE integration |
Chain |
bead-spring polymer melt of 100-mer chains, FENE bonds and LJ pairwise interactions with a 2^(1/6) sigma cutoff (5 neighbors per atom), NVE integration |
EAM |
metallic solid, Cu EAM potential with 4.95 Angstrom cutoff (45 neighbors per atom), NVE integration |
Rhodo |
rhodopsin protein in solvated lipid bilayer, CHARMM force field with a 10 Angstrom LJ cutoff (440 neighbors per atom), particle-particle particle-mesh (PPPM) for long-range Coulombics, NPT integration |
We install the LAMMPS package compiled with every compiler-MPI combination that exists on our system, and users can access these versions by loading the desired environment module.
LJ benchmarks#
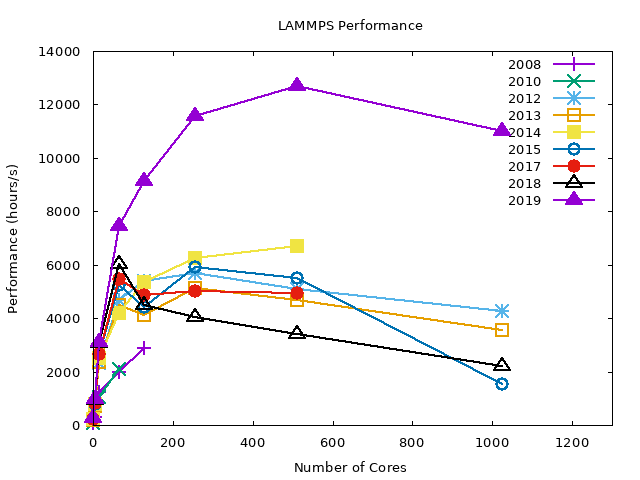
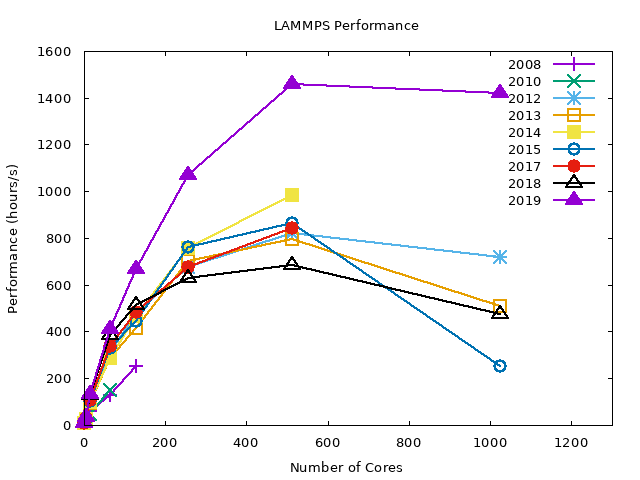
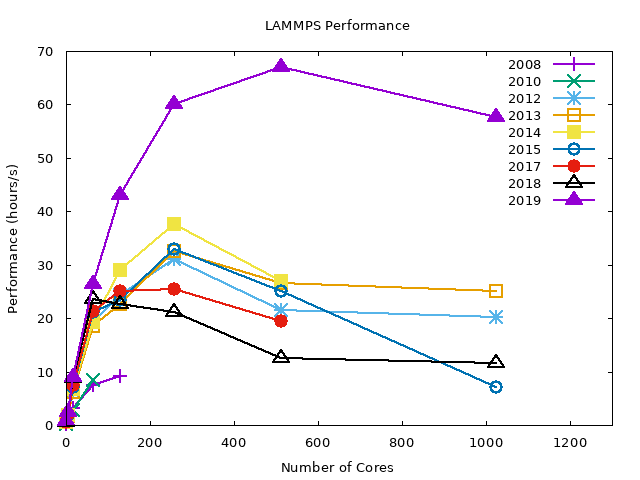
The following graphs summarize the LJ benchmark results over all compilers. It is noticeable that 2019 nodes perform significantly better (~40%) then other nodes. This is a direct result of newer hardware. Also notice that the WRF benchmarks had only a slight performance gain on the same nodes. The conclusion is that the exact gain depends on the type of job.
As shown later, even different configurations within LAMMPS yield highly variable results.

Specific compiler results#
The following graphs show LAMMPS performance of each compiler combination we offer (besides PGI):
GNU OpenMPI#
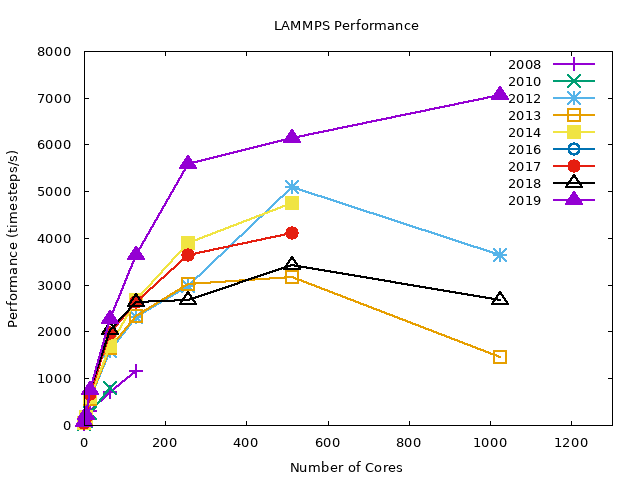
GNU MVAPICH2#
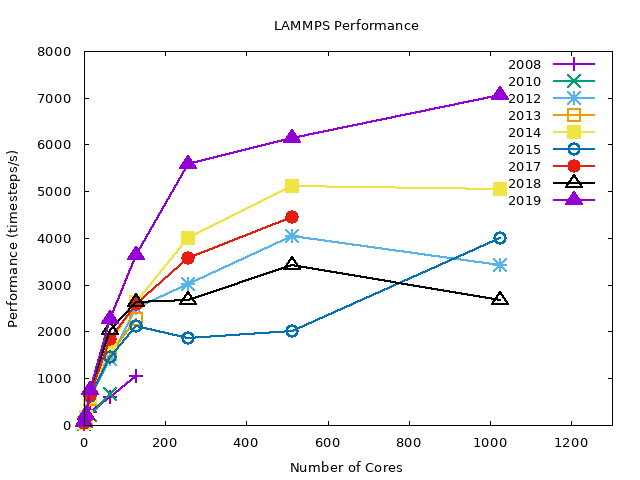
Intel OpenMPI#
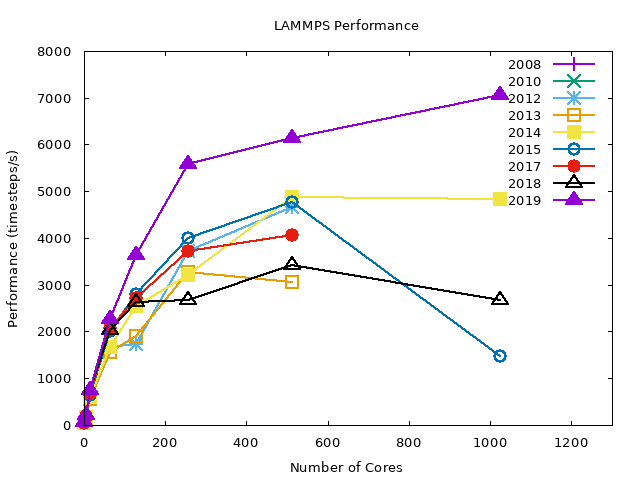
Intel MVAPICH2#
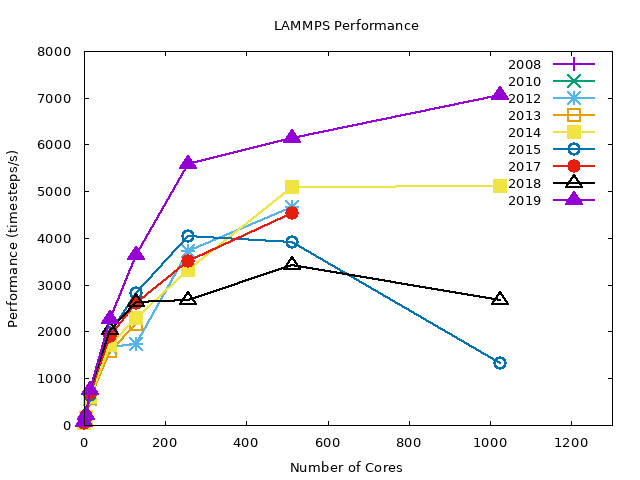
Chain Benchmarks#
EAM Benchmarks#
Rhodo Benchmarks#
Summary#
As you can see, the exact performance varies with the compiler, hardware, and the type of job. Therefore, the results shown here should be used only as a rule-of-thumb.
Also, our tests show that older hardware is not necessary bad for performance. For example, the 2014 nodes perform better than some newer nodes when running LAMMPS.
We encourage you to use these as a guide to assess the performance of your jobs even if you do not use WRF or LAMMPS. Nearly all of these tests were run during annual maintenance downtime or as soon as new sets of hardware are built and added to the cluster to not interfere with other jobs running on the HPC.
GPU Benchmarks#
We ran three applications to benchmark a single GPU node containing four NVIDIA GeForce GTX 1080 Ti GPU cards. We currently have several GPU configurations in our cluster, so these results are specific to that make/model. We had two main objectives:
- to compare CPU vs GPU performance
- to evaluate how well the performance scaled by adding multiple GPU cards to the job runtime configuration
Please note that your jobs run "in the wild" on our systems will likely vary from these benchmarks, depending on job parallelize-ability, memory requirements, etc.
NAMD#
NAMD is a parallel molecular dynamics application with built-in GPU support. We ran the NAMD apoa1 benchmark on CPU-only and CPU w/multiple GPUs to compare performance. Results are shown below.
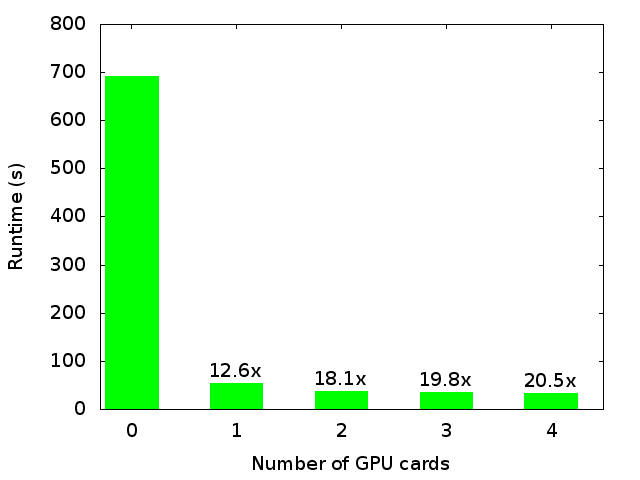
The figure shows that adding a single GPU increases the runtime by an order of magnitude and that adding additional GPUs has diminishing returns. With all four GPU cards, we were able to obtain more than 20x performance over CPU-only runtime.
LuxMark is an OpenCL-based rendering benchmark tool. We used two different scenes and obtained linear scaling when we added multiple GPU cards as show in the figure below:
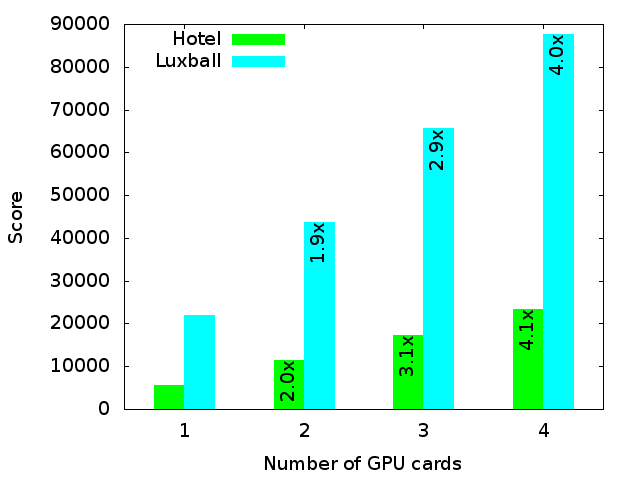
There is no CPU-only comparison, so the number on each bar shows the performance gain relative to a single GPU card. The scene "Hotel" is more complicated than "Luxball" and therefore has a lower score, but both scale linearly across multiple GPUs.
TensorFlow#
GPUs are becoming increasingly popular in machine learning/data science research. So, we ran some TensorFlow benchmarks. We compiled GPU-enabled Tensorflow version 1.8.0 from source. The benchmark we chose used convolutional neural networks (CNN) for training on a large number of images. The results are shown below:
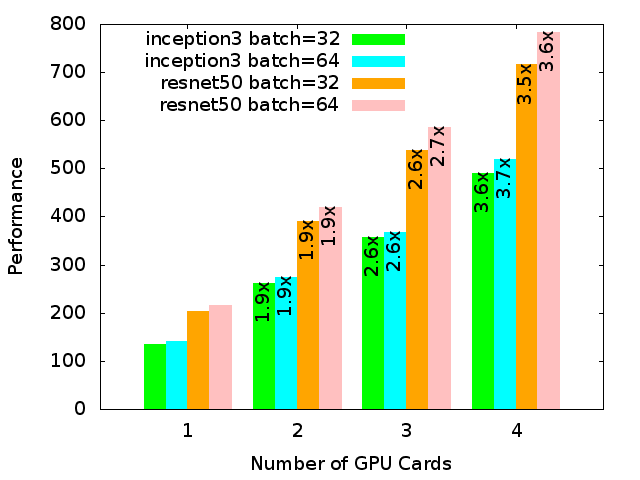
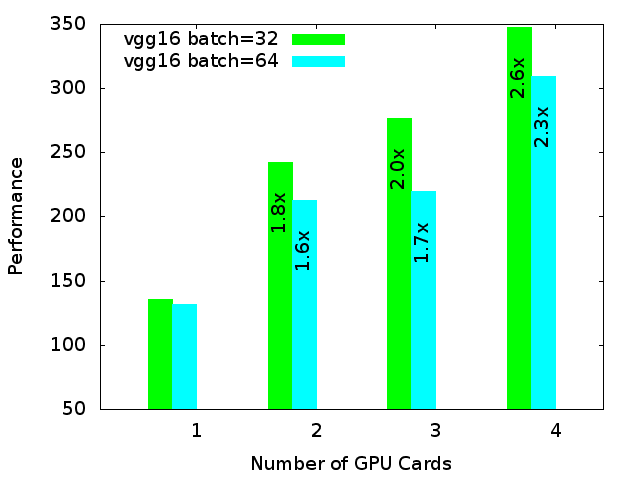
-
Repo URL: https://bitbucket.org/fsurcc/wrf-benchmarks ↩
-
1 GigaFlop = 1 million floating point operations per second ↩